초보 웹 개발자를 위한 스프링 5 프로그래밍 입문
저자 : 최범균
CH 3. 스프링 DI
1. 의존이란 ?
- DI Dependency Injection 의존 주입
- 객체 간의 의존
- 의존은 변경에 의해 영향을 받는 관계를 의미한다.
- 의존하는 대상이 있으면 그 대상을 구현하는 방법이 필요하다.
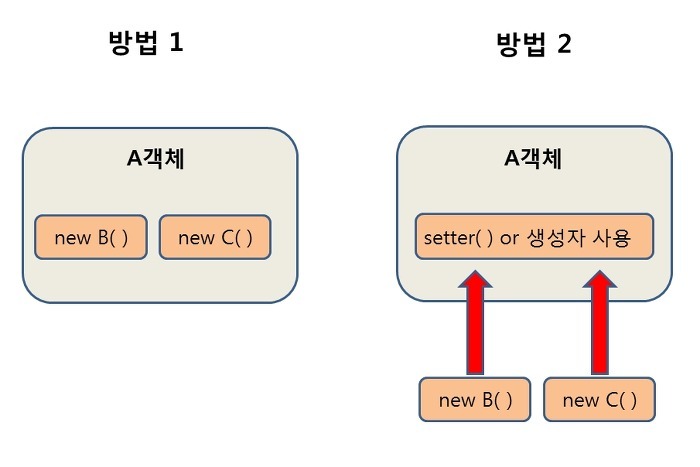
- 의존 객체를 직접 생성 ( 이 내용을 공부해보자 )
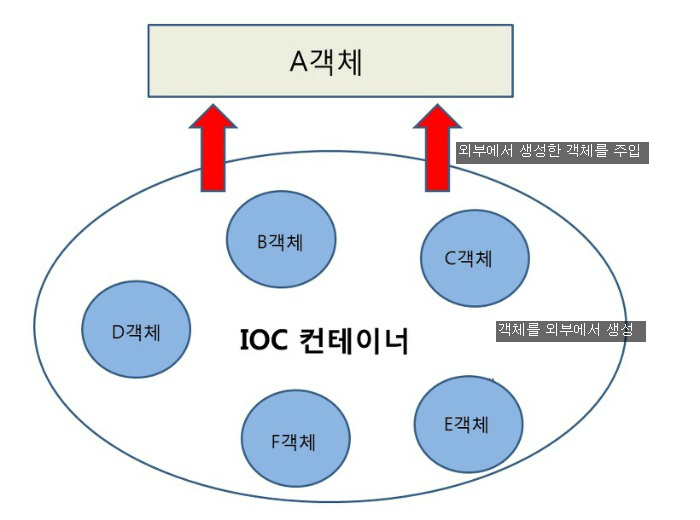
- DI와 서비스 로케이터
2. DI를 통한 의존 처리
- 의존하는 객체를 전달받는 방식을 이용하는 DI
public class MemberRegisterService {
// 직접 의존 객체 생성
private MemberDao memberDao = new MemberDao();
//생성자를 통해서 의존 객체를 전달 받는 형식
private MemberDao memberDao;
public MemberRegisterService(MemberDao memberDao){
this.memberDao = memberDao;
}
...
}
- 만약 MemberRegisterService 객체를 생성할 때 생성자에 MemberDao 객체를 전달해야 한다.
MemberDao dao = new MemberDao();
// 의존 객체를 생성자를 통해 주입한다.
MemberRegisterService svc = new MemberRegisterService(dao);복잡해 보이는데 왜 생성자 통해서 의존하는 객체를 주입할까?
-> 변경의 유연함을 위해서!!
3. DI와 의존 객체 변경의 유연함
- 의존 객체를 직접 생성하는 방식 = 필드나 생성자에서 new 연산자를 이용해 객체를 이용해 객체 생성
public class MemeberRegisterService {
private MemberDao memberDao = new MemberDao();
...
}이것과
public class ChangePasswordService {
private MemberDao memberDao = new MemberDao();
...
}이렇게 두개의 코드가 있는 상황.
캐시를 이용해 조회속도를 향상 시키고자 하는 상황이 발생...!!
memberDao -> cachedMemberDao 클래스를 만들어야 함~!~!
public class CachedMemberDao extends MemberDao {
...
}그렇다면 MemberRegisterService와 ChangePasswordService 모두 MemberDao에서 CachedMemberDao로 바꿔줘야함... ( 객체 생성시마다 하나하나 변경 해주어야 함... )
동일 상황에서 DI를 사용하면 수정 코드가 줄어든다...!!! ( 클래스가 여러개여도 의존 주입 되상이 되는 객체를 생성하는 코드가 한곳이라, 객체 생성 코드에서만 변경하면 된다,)
public class MemberRegisterService{
private MemberDao memberDao;
public MemberRegisterService(MemberDao memberDao){
this.memberDao = memberDao;
}
...
}
public class ChangePasswordService{
private MemberDao memberDao;
public ChangePasswordService(MemberDao memberDao){
this.memberDao = memberDao;
}
...
}
// --------------------------
// 위 뒤 클래스의 객체 생성시
// MemberDao memberDao = new MemberDao;
// 만 바꾸면 된다~!~!
MemberDao memberDao = new CachedMemberDao;
MemberRegisterService regSvc = new MemberRegisterService(memberDao);
ChangePasswordService pwdSvc = new ChangePasswordService(memberDao);
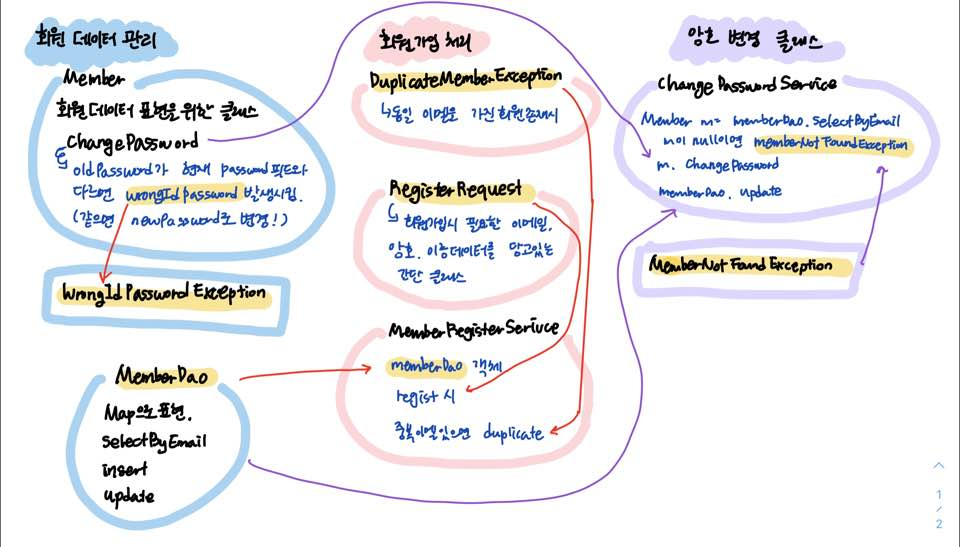
4. 예제 프로젝트 만들기
|---회원 데이터 관련 클래스
| |---Member
| |---WrongPasswordException
| |---MemberDao
|
|---회원 가입 처리 관련 클래스
| |---DuplicateMemberException
| |---RegisterRequest
| |---MemberRegisterService
|
|---암호 변경 관련 클래스
| |---MemberNotFoundException
| |---ChangePasswordService
5. 객체 조립기
- assembler
- 앞서 DI 설명 시 생성에 사용할 클래스를 변경하기 위해선, 객체를 주입하는 코드 한 곳만 변경하면 된다고 했다.
- 실제 객체를 생성하는 코드는 어디에 있을까???
- main 메소드에 의존 대상 객체를 생성하고 주입하는 방법이 나쁘진 않다.
- 더 나은 방법은 객체를 생성하고 의존 객체를 주입해주는 클래스를 따로 작성하는 것이다. (조립)
- 실제 객체를 생성하는 코드는 어디에 있을까???
public class Assembler {
private MemberDao memberDao;
private MemberRegisterService memberRegisterService;
private ChangePasswordService changePasswordService;
// MemberRegisterService와 ChangePasswordService 객체에 대한 의존을 주입한다.
// MemberRegisterService은 memberDao 객체를 주입받고,
// ChangePasswordService는 setter를 통해 주입받는다.
public Assembler(){
memberDao = new MemberDao();
// memberDao = new CachedMemberDao();
regSvc = new MemberRegisterService(memberDao);
pwdSvc = new ChangePasswordService();
pwdSvc.setMemberDao(memberDao);
}
...
}
위와 같이 생성한 Assembler를 사용하는 코드는...??
-> Assembler 객체를 생성 - get 메서드를 이용해 필요한 객체를 구함 - 그 객체를 사용
Assembler assembler = new Assembler();
ChangePasswordService changePwdSvc = assembler.getChangePasswordService();
changePwdSvc.changePassword("이메일","비번","newpwd");
- Assembler 클래스의 생성자에서 필요한 객체를 생성하고 의존을 주입한다.
- 따라서 Assembler 객체를 생성하는 시점에 사용할 객체가 모두 생성된다.
- 그 후 Assembler가 제공하는 메서드를 이용해서 필요한 객체를 구하고, 그 객체를 사용하는 것이 전형적 패턴이다!
6. 스프링의 DI 설정
- 스프링은 MemberRegisterService와 MemberDao와 같은 특정 타입의 클래스만 생성한 Assembler와 달리 범용 조립기 역할을 한다....!!!
- 스프링을 사용하려면 우선 스프링이 어떤 객체를 생성하고, 의존을 어떻게 주입할지 정의한 설정 정보 작성 필수
- 설정코드는 주로 config 패키지~
// 스프링 설정 클래스를 의미하는 에노테이션
@Configuration
public Class AppCtx{
// 해당 메서드가 생성한 객체를 스프링 빈이라고 설정하는 에노테이션
// memberDao 메서드를 이용해서 생성한 빈 객체는 "memberDao"란 이름으로 스프링에 등록
@Bean
public MemberDao memberDao(){
return new MemberDao();
}
@Bean
// MemberRegisterService 생성자를 호출할 때
// memberDao()메서드를 호출하므로 memberDao()가 생성한 객체를
// MemberRegisterService 생성자를 통해 주입
public MemberRegisterService memberRegSvc(){
return new MemberRegisterService(memberDao);
}
@Bean
public ChangePasswordService changePwdSvc(){
ChangePasswordService pwdSvc = new ChangePasswordService();
// setMemberDao() 메서드를 이용해 의존관계를 주입한다
pwdSvc.setMemberDao(memberDao());
return pwdSvc;
}
- 설정 클래스를 만들었다고 끝이 아니다!!!!!!!
- 컨테이너를 생성해야한다. ( 컨테이너 : 객체를 생성하고 의존 객체를 주입하는 역할 )
-
// 컨테이너 생성 ApplicationContext ctx = new AnnotationConfigApplicationContext(AppCtx.class); // 컨테이너 생성 후 getBean() 메서드를 이용해 사용할 객체를 구할 수 있다. // 컨테이너에서 이름이 memberRegSvc인 빈 객체를 구한다. MemberRegisterService regSvc = ctx.getBean("memberRegSvc", MemberRegisterService.class);
DI 방식 1 : 생성자 방식
- 생성자를 통해 의존 객체를 주입받아 필드(this.memberDao)에 할당한다
private MemberDao memberDao;
// 생성자를 통해 의존 객체를 주입 받음
public MemberRegisterService(MemberDao memberDao){
// 주입 받은 객체를 필드에 할당
this.memberDao = memberDao;
}
public Long regist(RegisterRequest req){
// 주입 받은 의존 객체의 메서드 사용
Member member = memberDao.selectByEmail(req.getEmail());
...
memberDao.insert(newMember);
...
}
- 생성자에 의해 전달할 의존 객체가 두 개 이상이어도 동일한 방식으로 주입하면 된다.
// 생성자 파라미터가 두개인 예제를 살펴보자~!
public class MemberDao{
...
public Collection<Member> selectAll(){
return map.values();
}
}
// =====================================================================
// 생성자로 두 개의 파라미터를 전달받는 클래스 작성
// MemberDao, MemberPrinter 객체를 전달 받는다.
public MemberListPrinter(MemberDao memberDao, MemberPrinter printer){
this.memberDao = memberDao;
this.printer = printer;
}
// ======================================================================7. @Configuration 설정 클래스의 @Bean 설정과 싱글톤
8. 두 개 이상의 설정 파일 사용하기
9. getBean( ) 메서드 사용
10. 주입 대상 객체를 모두 빈 객체로 설정해야 하나?
'🔥 > Spring' 카테고리의 다른 글
| [spring] 빈 라이프 사이클과 범위 (0) | 2021.08.31 |
|---|---|
| [spring] 컴포넌트 스캔이란 (0) | 2021.08.31 |
| [Spring] DI의 세가지 방법 (0) | 2021.08.18 |
| [Spring] 의존성 주입(DI)이란 ? (0) | 2021.08.18 |