BOJ 14719
🕵️♀️ 문제
2차원 세계에 블록이 쌓여있다. 비가 오면 블록 사이에 빗물이 고인다.비는 충분히 많이 온다. 고이는 빗물의 총량은 얼마일까?


💡 입력
첫 번째 줄에는 2차원 세계의 세로 길이 H과 2차원 세계의 가로 길이 W가 주어진다. (1 ≤ H, W ≤ 500)
두 번째 줄에는 블록이 쌓인 높이를 의미하는 0이상 H이하의 정수가 2차원 세계의 맨 왼쪽 위치부터 차례대로 W개 주어진다.
따라서 블록 내부의 빈 공간이 생길 수 없다. 또 2차원 세계의 바닥은 항상 막혀있다고 가정하여도 좋다.
📌 출력
2차원 세계에서는 한 칸의 용량은 1이다. 고이는 빗물의 총량을 출력하여라.
빗물이 전혀 고이지 않을 경우 0을 출력하여라.

🙋♀️ 풀어보자~
빗물이 고이기 위해서는 기둥이 필요하다.
이 기둥이 어떻게 생기는지 생각해보자.

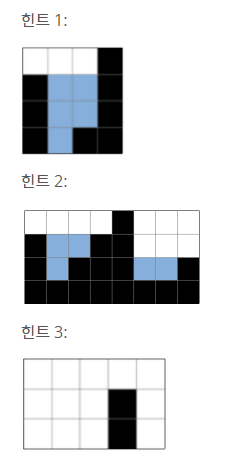
위 사진과 같이 max인 4를 기준으로 좌우의 가장 큰 값인 3과 2의 값이 중요함을 알 수 있다.
왼쪽은 3을 기준으로 빗물이 받아지고 오른쪽은 2를 기준으로 빗물이 받아지기 때문~
더 자세하게 보자면..

각 자리를 i로 보고 0부터 7까지 번호를 매겼을 때 2번째 블럭을 보자.
i=2번째 블럭은 2개로 이 블럭을 기준으로 빗물 기둥이 되어줄 좌우의 max 숫자를 살펴보면 3과 4임을 알 수 있다.
여기서 max중 작은 수가 기준이 되기 때문에 3이라는 숫자를 이용해주게 된다.
정리하자면~
- 양쪽에 더 높은 블럭이 존재하면 빗물이 고임
- 반복문을 돌면서 현재의 블럭 기준 left_max와 right_max를 구하고 이 두 값중 작은 수를 구함
- 구해진 수 - 현재 블럭의 수 가 빗물이 담길 칸수다.
- 첫 블럭과 마지막 블럭은 볼필요 없다. (그림과 같은 예시를 이용하자면, i=0일 때와 i=7일 때)
# 빗물
# 입력을 받아 준다.
H, W = map(int, input().split())
block = list(map(int, input().split()))
answer = 0
# 맨 앞뒤를 제외한 for문을 돌면서 왼쪽과 오른쪽에서 최댓값을 찾는다.
for i in range(1, W-1):
left_max = max(block[:i]) # 현재 블럭을 기준으로 왼쪽에서 max 값 찾기
right_max = max(block[i+1:]) # 현재 블럭을 기준으로 오른쪽에서 max 값 찾기
m = min(left_max, right_max) #left_max와 right_max 중 작은 값을 변수에 담자.
# 현재 블럭이 지정한 기준값보다 작으면 빗물이 고인다.
if block[i] < m:
answer += m - block[i]
print(answer)
'🕵️♀️ > BOJ' 카테고리의 다른 글
| [Python] BOJ 2606 바이러스 (BFS/DFS) (0) | 2021.11.17 |
|---|---|
| 코테대비 백준문제추천 (0) | 2021.11.05 |
| [Python] BOJ 1149 RGB거리 (dp) (0) | 2021.11.04 |
| [BOJ] Python 백준 11650번 (0) | 2021.08.19 |
| [BOJ] Python 백준 2751번 (0) | 2021.08.16 |