Elasticsearch를 처음 설치하다 보면 항상 보는 에러들이 몇 가지 있습니다.
1) root 계정으로 실행할 수 없으며
2) openfiles, max process 값을 수정해야하고
3) swappiness 값 설정 변경 요청도 있습니다.

Elasticsearch 실행 시 발생한 Max user processes Error
그 중에 elasticsearch는 openfiles와 max process는 최소 65535로 설정하라며, 커널에서 해주는 기본 설정보다 큰 값을 요구하는데요,
오늘은 해당 파라미터가 정확히 어떤 것을 가르키는지 그리고 설정된 값 이상이 되면 어떤 일이 일어나는지 알아보겠습니다.
1. Max user processes
Max user processes의 의미는 하나의 계정에서 최대로 실행할 수 있는 process의 개수를 말합니다. OS에서의 확인은
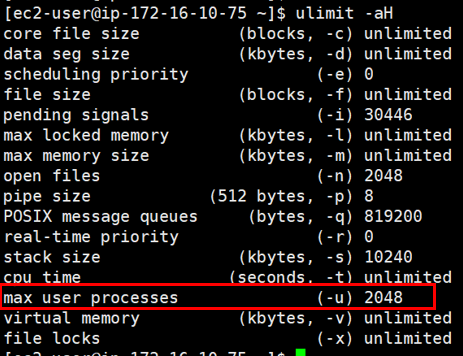
# ulimit -a (sofe ulimit)
# ulimit -aH (hard ulimit)
위 명령으로 확인 가능합니다. (현재 제 서버의 설정 값은 아래와 같습니다.)
max user processes
그럼 아래 테스트 코드를 통해 설정된 max user processes의 값을 넘기면 어떻게 되는지 확인해보겠습니다.
4000개 Thread 생성 후 유지
대략적인 코드의 내용은 HTTP 요청이 오면 비동기로 4천개의 Thread를 동시에 생성하고 20분간 유지하는 코드입니다.
그리고 실제로 Thread를 늘려보면,
Thread 생성 중 OOM 발생
그림처럼 ulimit -a 명령의 max user processes 결과와 같이 ec2-user 계정은 1024개까지 스레드를 생성한 후, OOM 에러 메세지를 발생하며 멈춰버리게 됩니다. (이 경우 ec2-user 계정에서는 쉘 명령어 입력 등 어떤 작업도 동작하지 않습니다.)
<리눅스에서는 스레드와 프로세스를 동일하게 봅니다.>
2. Open files
다음은 Open files입니다. 이 값은 프로세스가 가질 수 있는 최대 파일의 개수를 의미합니다.
리눅스는 모든 프로세스나 세션(소켓)들을 파일로 관리하기 때문에 이 값의 설정은 서버에서의 Connection연결 작업에 매우 중요한 내용이 됩니다.
(설정 값을 넘어가게 되면 리눅스에서 파일을 열 수 없어 프로세스 실행이나 Connection 연결이 안되기 때문!)
그럼 소켓을 open files 값 보다 많이 만들어 테스트를 해보겠습니다.
(1) Java 환경 TEST
- RestTemplate로 소켓 생성 요청을 보내고, 요청을 받은 서버에서 20분간 응답을 대기 시킵니다.
- 요청을 동시에 1100개를 보내 open files가 1024로 제한인 서버에 에러가 발생하면 테스트 성공입니다.
(기본적으로 java, spring 관련 file이 몇 개 오픈됩니다.)
아래는 테스트 코드 일부입니다.
connection 소켓 생성 후 응답 대기 Code
그리고 동시에 요청을 보낼 API 요청 스크립트를 작성합니다.

API 요청 쉘
쉘을 실행하여 테스트를 진행하면…
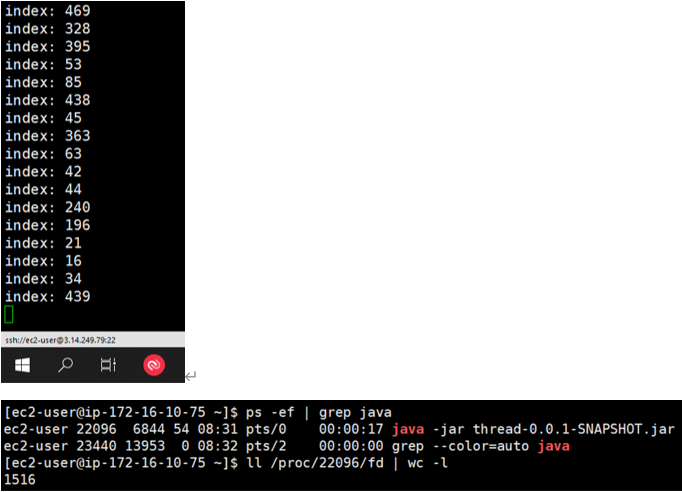
openfiles 개수가 1024 값을 넘어 1516개 까지 열림!
위 그림처럼 소켓이 1024개가 넘어도 에러 메시지 없이 동작하는 것을 볼 수 있습니다. 그럼 한번 더 스크립트를 실행해보겠습니다.
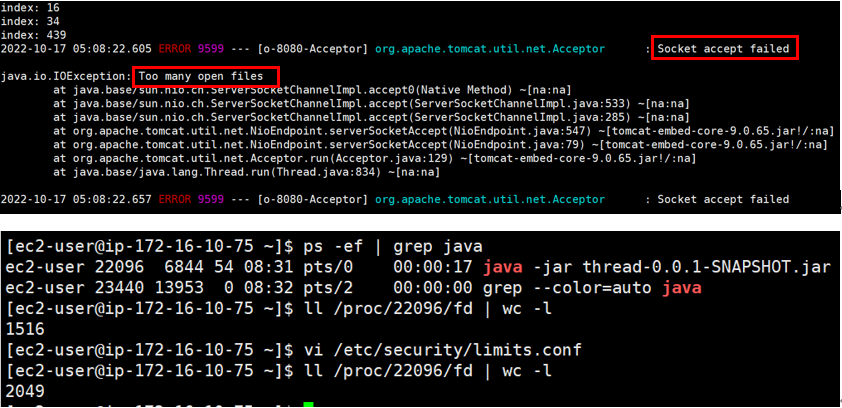
2048개 까지 생성된 모습
이제 에러가 발생했습니다. 파일은 딱 2048개 까지만 열린 것을 확인할 수 있는데요, openfiles의 값은 soft로 설정된 값이 아닌
그림처럼 Hard 옵션 값까지 file이 생성된다는 것을 알 수 있습니다.
그런데…! 알고 보니 java 환경에서는 hard 값을 따라가는게 맞지만 Python에서는 아니라고 합니다…
(2) Python 환경 TEST
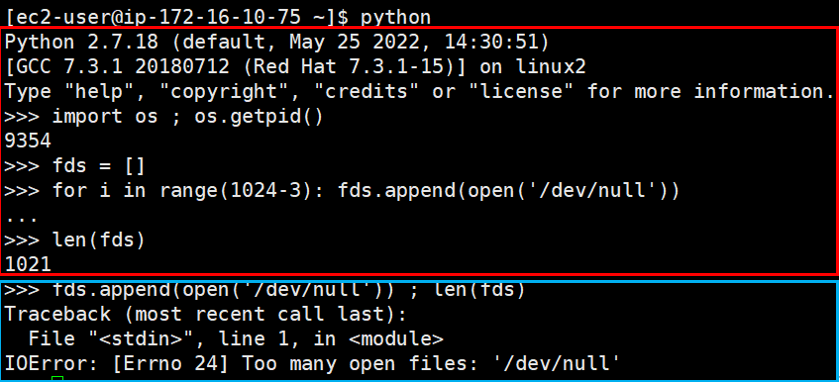
빨간 박스 : 1024개의 열린 파일 생성 / 파란 박스 : 1024개 이후 파일을 하나 더 열어본다
위 처럼 파이썬 스크립트로 file을 임의로 열어봅니다. 1021개 까지는 파일이 문제없이 열리지만(stdin, stdout, stderr 표준 입/출력 3개 제외)
이후로 여는 파일에서는 Too many open files 에러가 발생합니다!
(3) Java와 Python 환경의 차이?
테스트 결과 Java는 hard 옵션까지 파일이 오픈되고 Python은 soft 값까지 오픈됨을 알 수 있었습니다. 그 이유를 찾기 위해 strace 명령을 통해 java 프로세스 동작을 추적해보면

kernel 5.15ver에서 테스트 (이전 버전은 prlimit64 함수 대신 getrlimit, setrlimt 함수 사용)
위 그림처럼 java 프로세스가 시작됨과 동시에 prlimit64라는 함수가 rlim_cur=1024값을 rlim_max=2*1024(hard limit) 값까지 업데이트하는 로그가 찍혀있는 것을 볼 수 있었습니다.

JDK에서 MaxFDLimit 옵션 활성화 (기본값)
그 이유는 설치된 JVM에서 MaxFDLimit 옵션을 통해 limit을 올려주었기 때문이라고 합니다! (기본적으로 활성화된 옵션)
즉, 리눅스 OS에서는 JDK 실행 시 커널에서 prlimit64 함수를 통해 자동으로 limit 사이즈를 증가시켜준다는 것을 알 수 있었습니다.
3. 정리
- (Linux 환경) JAVA에서 동시에 생성 가능한 쓰레드 수는 Max user processes를 따라간다.
- (Linux 환경) JAVA에서 소켓 통신(API나 모든 Connection)은 open files 옵션을 따라간다.
-> JAVA에서는 JDK 코드에서 자동으로 soft limit값은 hard limit값까지 업데이트 됨
-> Python은 soft limit 값에서 제한이 걸림
나의 개발 환경에 맞게, Max user processes와 open files의 적절한 값을 찾아 설정하는 것이 중요하겠습니다!
<공동저자>
https://giraffe-lee.tistory.com/7
<참조>
'🔥 > OS' 카테고리의 다른 글
| [운영체제] IPC Inter-Process Communication (0) | 2021.09.09 |
|---|---|
| [운영체제] 시스템 콜 System Call (0) | 2021.08.31 |
| [운영체제] 인터럽트 Interrupt (0) | 2021.08.25 |
| [운영체제] 프로세스 주소 공간 (0) | 2021.08.25 |
| [운영체제] 프로세스와 스레드의 차이 (0) | 2021.08.18 |