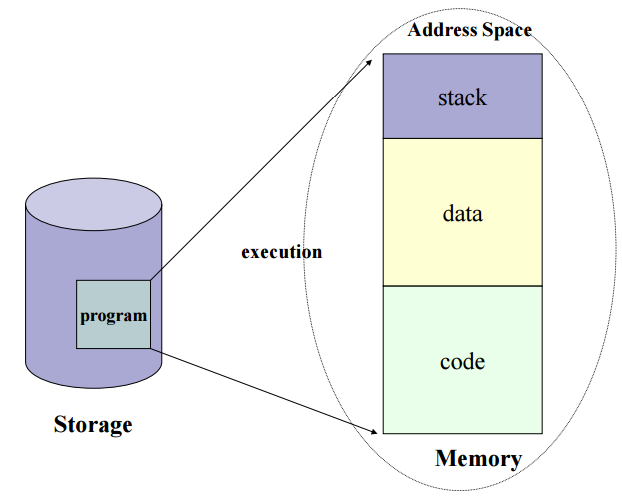
컨테이너 초기화와 종료
스프링 컨테이너는 초기화와 종료라는 라이프 사이클을 갖는다.
- 컨텍스트 객체가 생성되는 시점에 컨테이너를 초기화함
- 스프링 컨테이너는 설정 클래스에서 정보를 읽어와 알맞은 Bean 객체를 생성하고, 각 Bean을 연결(의존 주입)하는 작업 수행
- 초기화가 끝난 후 컨테이너를 사용 가능(getBean()등의 작업으로 Bean 객체를 구하는 행위 등)
- 컨테이너 사용이 끝나면 컨테이너를 close() 매서드를 사용해 종료, Bean 객체의 소멸
기본적으로 Spring의 ApplicationContext 구현은 초기화 프로세스에서 모든 싱글톤 빈을 생성 및 설정
> 따라서 Bean에 문제가 있을 경우 초기화 단계에서 알 수 있다는 장점이 존재
// 1. 컨테이너 초기화
AnnotationConfigApplicationiContext ctx =
new AnnotationConfigContext(AppContext.class);
// 2. 컨테이너에서 빈 객체를 구해서 사용
Greeter g = ctx.getBean("greeter", Greeter.class);
String msg = g.greet("스프링");
System.out.println(msg);
// 3. 컨테이너 종료
ctx.close();
- AnnotationConfigApplicationiContext의 생성자를 이용해서 context 객체를 생성한다.
이 시점에서 스프링 컨테이너 초기화가 진행되고, 이 스프링 컨테이너는 설정 클래스에서 정보를 읽어와 알맞은 빈 객체를 생성하고 각 빈을 연결(의존주입)하는 작업을 수행한다. - (위에서 초기화되어 사용가능한 컨테이너) getBean()과 같은 메서드를 이용해서 컨테이너에 보관된 빈 객체를 구한다.
- 컨테이너 사용을 종료할 때 사용하는 메서드이다. AbstractApplicationContext 클래스에 정의되어 있다.
AnnotationConfigApplicationiContext가 AbstractApplicationContext를 상속 받기 때문에 close() 사용이 가능하다.
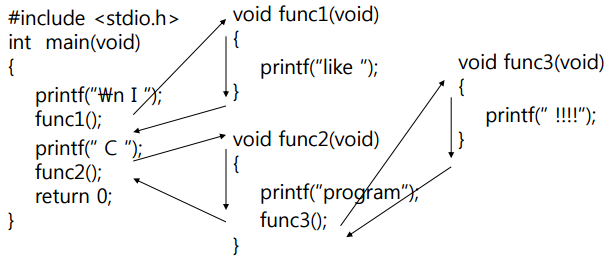
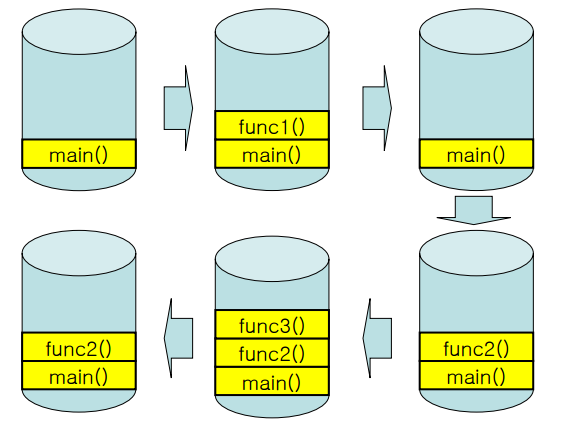
컨테이너 초기화 -> 빈 객체의 생성, 의존 주입, 초기화
컨테이너 종료 -> 빈 객체의 소멸
스프링 빈 객체의 라이프 사이클
객체생성 - 의존설정 - 초기화 - 소멸
스프링 컨테이너는 빈 객체의 라이프 사이클을 관리한다.
1. 빈 객체의 초기화와 소멸 : 스프링 인터페이스
- org.springframework.beans.factory.InitializingBean
- org.springframework.beans.factory.DisposableBean
빈 객체를 생성한 뒤, 초기화 과정이 필요하면
InitializingBean 인터페이스를 상속하고 afterPropertiesSet()메서드를 구현하면 된다.
빈 객체의 소멸 과정이 필요하면 DisposableBean 인터페이스를 상속하고 destroy()메서드를 구현하면 된다.
ex. 데이터 베이스 커넥션 풀, 채팅 클라이언트
메서드 정의 인터페이스
- org.springframework.beans.factory.InitializingBean
- org.springframework.beans.factory.DisposableBean
//초기화 인터페이스
public interface InitializingBean {
void afterPropertiesSet() throws Exception;
}
//소멸 인터페이스
public interface DisposableBean {
void Destroy() throws Exception;
}
해당 코드를 수행하면 콘솔 화면에 매서드에서 정의한 "Client.afterPropertiesSet() 실행" 및 "Client.destroy() 실행"이 출력 됨
빈 객체 생성을 마무리한 뒤에 초기화 메서드를 실행한다.
또, 가장 마지막에 destroy() 메서드를 실행한다.
2. 빈 객체의 초기화와 소멸 : 커스텀 메서드
인터페이스로 상속받아 구현하는 것 말고 외부에서 제공받은 클래스를 스프링 빈 객체로 설정하고 싶을 때도 있다.
스프링 설정에서 직접 메서드를 지정할 수 있다.
@Bean태그에서 initMethod 속성과 destroyMethod 속성을 사용해서 초기화 메서드와 소멸 메서드의 이름을 지정하면 된다.
//Client2.java
...
// 직접 초기화 메서드 지정
public void connect(){
System.out.println("Client2.connect() 실행");
}
// 직접 소멸 메서드 지정
public void close(){
System.out.println("Client2.close() 실행");
}
...
이 메서드들을 @Bean 애노테이션의 initMethod 속성과 destroyMethod 속성에 사용될 메서드 이름인 connect와 close를 지정해주면 된다.
@Bean(initMethod = "connect", destoryMethod = "close") public Client2 clien2(){ ... }
초기화 메서드를 직접 실행할 때 초기화 메서드가 두 번 불리지 않다록 조심하자. afterPropertiesSet()이 두번 불릴 위험 있음
빈 객체의 생성과 관리 범위
// 한 식별자에 대해 한 개의 객체만 존재하는 빈
// 싱글톤 범위를 갖는다.
//client1 == client : true
Client client1 = ctx.getBean("client", Client.class);
Client client2 = ctx.getBean("client", Client.class);
------------------------
// client 빈의 범위가 프로토타입일 경우
// 매번 새로운 객체를 생성
// client1 != client : true
Client client1 = ctx.getBean("client", Client.class);
Client client2 = ctx.getBean("client", Client.class);
별도의 설정을 하지 않으면 싱글톤 범위를 갖는데, 특정 빈을 프로토 타입으로 빈을 설정할 수 도 있다. @Scope애노테이션을 사용해주면 된다.
@Bean
@Scope("prototype")
public Client client(){
...
}
- 싱글톤 범위를 명시적으로 지정해주고 싶으면 @Scope("singleton)이라고 해주면 된다.
- 프로토 타입은 별도의 소멸 처리를 코드에서 직접 해야 한다.
Reference.
'초보 웹 개발자를 위한 스프링5 프로그래밍 입문'
'🔥 > Spring' 카테고리의 다른 글
| [spring] 컴포넌트 스캔이란 (0) | 2021.08.31 |
|---|---|
| [Spring] "회초리단" 스프링 스터디 1차 (0) | 2021.08.20 |
| [Spring] DI의 세가지 방법 (0) | 2021.08.18 |
| [Spring] 의존성 주입(DI)이란 ? (0) | 2021.08.18 |